Vistaprint decided to decrease it’s employee headcount by $20 million dollars in employee salary, I was part of that cut. I was aware that the market was hot at the moment, so I was optimistic from day 1. I received severance, and this was an opportunity to give some real thought about what I would like my next move to be.I happened to get laid-off 4 days after I had just dyed my hair bright pink for the first time, that was a bummer.I actually went to one job interview with my pink hair, and they loved it. However, I did decide to bring my hair back to a natural color for the rest of my search.
Very First Thing I Did:
I am approached by recruiters pretty frequently on LinkedIn. I always reply.Although if you’re just getting into the field, you may not have past messages from recruiters in your LinkedIn mail, but I mention this so that you can start to do this throughout the rest of your career.Now that I was looking, my first action was to go through that list, message everyone and say:“Hi (recruiter person), I’m currently looking for a new opportunity. If there are any roles you’re looking to fill that would be a good fit, I’d be open to a chat.”
There were a number of people that replied back saying they had a role, but after speaking with them, it didn’t seem like the perfect fit for me at the moment.In addition to reaching out to the recruiters who had contacted me, I also did a google search (and a LinkedIn hunt) to find recruiters in the analytics space. I reached out to them as well to let them know I was looking. You never know who might know of something that isn’t on the job boards yet, but is coming on soon.
First Meeting With the Career Coach
As part of the layoff, Vistaprint set me up with a career coach. The information she taught me was incredibly valuable, I’ll be using her tips throughout my career. I met with Joan Blake from Transition Solutions. On our first meeting, I brought my resume and we talked about what I was looking for in my next role.Because my resume and LinkedIn had success in the past, she did not change much of the content on my resume, but we did bring my skills and experience up to the top, and put my education at the bottom.
They also formatted it to fit on one page. It’s starting to get longer, but I’m a believer in the one page resume.I also made sure to include a cover letter with my application. This gave me the opportunity to explicitly call out that my qualifications are a great match with their job description. It’s much more clear than having to read through my resume for buzzwords.I kept a spreadsheet with all of the companies I applied to. In this spreadsheet I’d put information like the company name, date that I completed the application, if I had heard back, the last update, if I had sent a thank you, the name of the hiring manager, etc.This helped me keep track of all the different things I had in flight, and if there was anything I could be doing on my side to keep the process moving.
Each Application:
For each job I applied to, I would then start a little hunt on LinkedIn. I’d look to see if anyone in my network currently worked for the company. If so, they’d probably like to know that I’m applying, because a lot of companies offer referral bonuses. I’d message the person and say something like:Hey Michelle,I’m applying for the Data Scientist position at ______________. Any chance you’d be willing to refer me?
If there is no one in my network that works for the company, I then try and find the hiring manager for the position. Odds are it was going to be a title like “Director (or VP) of Data Science and Analytics”, or some variation, you’re trying to find someone who is a decision maker.This requires LinkedIn Premium, because I’m about to send an InMail. My message to a hiring manager/decision maker would look something like:
Hi Sean,I’m interested in the remote Data Science position, and I’m hoping I can get my resume in the right hands. I have an MS in Statistics, plus 7 years of real-world experience building models. I’m a wiz at SQL, modeling in R, and I have some exposure to Python.I’d appreciate the opportunity to speak with the appropriate person about the open position, and share how I’ve delivered insights and added value for company’s through the use of statistical methods.Thanks, Kristen
Most people actually responded, Joan (the career coach) was surprised when I told her about my cold-calling LinkedIn success.
I Started Applying to Jobs, and Started Having “Phone Screens”
Phone screens are basically all the same. Some were a little more intense and longer than others, but they were all around a half hour, and they’re typically with someone in HR. Since it’s HR, you don’t want to go too deep in the technical stuff, you just want to be able to pass this stage, follow up with a note thanking them for their time, and try to firm up when you’ll be able to speak with the hiring manager :)Tell me about yourself:People just want to hear that you can speak to who you are and what you’re doing.
Mine was some variation of:
I am a Data Scientist with 7 years of experience using statistical methods and analysis to solve business problems across various industries. I’m skilled in SQL, model building in R, and I’m currently learning Python.
What are you looking to do?I’d make sure that what I’m looking to do ties directly to the job description. At the end of the day, it was some variation of:
“I’m looking to continuously learn new tools, technologies and techniques. I want to work on interesting problems that add business value”.
Then I’d talk about how interesting one of the projects on the job description sounded.What are you looking for in terms of salary?Avoid this question if you can, you’ll be asked, but try to steer in a different direction. You can always reply with “I’ve always been paid fairly in the past, I trust that I’ll be paid fairly working for [insert company name]. Do you have an idea of the salary range for the position”.They’ll know the range for the position, but they’ll probably tell you that they don’t. Most of the time I’d finally concede and give them my salary, this doesn’t mean that you won’t be able to negotiate when you receive an offer.
All The While, I’m Still Learning, And Can Speak to This in Interviews:
If I was going to tell everyone that I was very into learning technologies, I better be “walking the walk” so to speak. Although I am constantly learning, because it’s in my nature. Make sure that if you say you’re learning something new, you’re actually studying it.
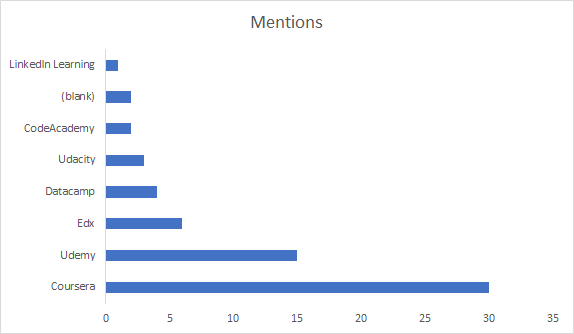
The course I took was: Python for everybody
Disclaimer: This is an affiliate link, meaning that at no cost to you, I will earn a commission if you end up signing up for this course.
This course goes over your basic lists, arrays, tuples, defining a function.. but it also goes over how to access and parse web data. I had always wanted to know how to access Twitter data for future analysis, so this was super cool. The specialization (that’s the name they give for a series of courses on Coursera) also gives a brief overview in how to construct a database. This was a super bonus for me, because if I want to operationalize a model, I’m going to want to know how to write from Python to a database table. All-in-all, I found this course to be a great use of my time, and I finished it being able to speak to things intelligently, that I was not able to speak to prior to taking the course.
In Person Interviews:
I've written a whole article on in person interviews: here
At some point, you might receive a call saying they plan on putting an offer together for you, if you're still interested.Great! You’ve got an offer coming. At this point, you want to call all the other companies that you would consider an offer from and say “I’ve been informed that I am expecting an offer, is there anything you can do to accelerate your process?”I mentioned this to 2 companies. One of them did speed up their process and it resulted in an additional offer. The other company said that they would not speed up their process, I thanked them for their time and said I'd hope to cross paths in the future.
Negotiating:
The phone rings, and you answer. This is it, you’re getting your first offer. It’s time to negotiate. Only a relatively small percentage of people ever negotiate their salary, the percentage is even smaller when we’re talking about women.Ladies! Negotiate! I’m here rooting for you, you got this.Joan from Transition Solutions had coached me on this. She said “Don’t try and solve the problem for them”.When they call, let them know how excited you are that they called, and that you’re interested in hearing their offer.
Once you’ve heard the salary, vacation time, and that they’re going to send over the benefits information, you can say something along the lines of:
"Thank you so much for the offer, I really appreciate it. You know, I was hoping that you could do more on the salary."
Then wait for a response, and again be positive. They’ll most likely say that they need to bring this information back to the hiring manager."
Great! I look forward to hearing back from you. I’ll take some time to look over the benefits package. Want to speak again on ____. I’m feeling confident that we can close this."
Then you’d be walking away from the conversation with a concrete time that you’ll speak to them next, and you let them know that you were happy to hear from them, all of this is positive!I successfully negotiated my offer, and started a week later. I couldn’t be happier with where I am now and the work I’m doing. It took a lot of applying and a lot of speaking with companies who weren’t “the one”, but it was worth it.To sum up my job search. I learned that a targeted cover letter and directly applying on a company website greatly increase the response rate on your applications.
I learned that you can effectively leverage LinkedIn to find the decision maker for a position and they’ll help keep the process moving if you’re a good fit. I also gained a ton of confidence in my ability to articulate my skills, and this came with practice. I wish you lots of success on your hunt, and I hope that there was a couple of tips in this article that you are able to use :)