
A Different Use of Time Series to Identify Seasonal Customers
I had previously written about creatively leveraging your data using segmentation to learn about a customer base. The article is here. In the article I mentioned utilizing any data that might be relevant. Trying to identify customers with seasonal usage patterns was one of the variables that I mentioned that sounded interesting. And since I'm getting ready to do another cluster analysis, I decided to tackle this question.
These are my favorite types of data science problems because they require you to think a little outside the box to design a solution. Basically, I wanted to be able to tag each customer as whether or not they exhibited a seasonal pattern, this would be a first step. Later I may further build this out to determine the beginning of each customer's "off-season." This will allow us to nurture these customer relationships better, and provide a more personalized experience.
I'm a data scientist at Constant Contact, which provide email marketing solutions to small businesses. Since it is a subscription product, customers have different usage patterns that I'm able to use for this analysis.
At first, my assumption was that a good portion of these customers might be living in an area that has four seasons. You know, the ice cream shop in New England that shuts down for the winter. After thinking about it some more, if I'm looking for seasonal usage patterns, this is also going to include people with seasonal business patterns that aren't necessarily driven by the weather. People who have accounts in the education field taking summers off are going to be picked up as seasonal. Businesses in retail who have pretty consistent usage all year, but pick up their engagement at Christmas are also exhibiting a seasonal pattern. So the people who the model would determine were seasonal were not based solely on the weather, but could also be by the type of business. (Or maybe there are people that are fortunate enough to take random long vacations for no reason in the middle of the year, I want to make sure I find those people too, if they exist).
To do this analysis, I aggregated the email sending patterns of each customer with at least 2 years by customer, by month. Each customer is it's own time series. However, there were a couple complexities. One detail in particular is worth noting, customers might take a month or two (or more) off from usage. So first I had to write some code to fill in zeros for those months. I couldn't be specifying that I was looking for a yearly pattern, but only giving 8 months worth of data per year in the model, I needed those zeros. I found these missing zeros using Python, and then decided I wanted to use R for the time series/determining if a seasonal pattern was present portion. I got to use the rpy2 package in Python for the first time. Check that off the list of new packages I've wanted to try.
I fit a TBATS model for each customer in R. This is probably overkill, because TBATS was meant to deal with very complex (and potentially multiple) seasonal patterns. However, it was really simple to ask the model if it had a yearly seasonal component. Bonus, TBATS is more robust to stationarity than other methods.
Here is a picture of a customer who the model determined to be seasonal, and on the right is a customer who is obviously not seasonal, and the model agrees.
 After I had the output of my model, I went back and did a full analysis of what these customers looked like. They over-indexed in the Northeast, and were less likely to be in the West and South. Seasonal users were also more likely to self-report being in an industry like:
After I had the output of my model, I went back and did a full analysis of what these customers looked like. They over-indexed in the Northeast, and were less likely to be in the West and South. Seasonal users were also more likely to self-report being in an industry like:
- Retail
- Sports and Recreation
- Non Profits
Non seasonal users were also more likely to self-report being in an industry like:
- Auto Services
- Financial Advisor
- Medical Services
- Insurance
Customers with only 2-3 years tenure were less likely to be seasonal than more tenured customers. This could potentially be due to a couple different factors. Maybe there just wasn't enough data to detect them yet, maybe they have some period of getting acquainted with the tool (involving a different usage pattern) before they really hit their stride, or maybe they're just really not seasonal. There were more insights, but this is company data ;)Here is a map of seasonal customers over-indexing in the Northeast. Stakeholders typically enjoy seeing a nice map. Note: The split was not 50/50 seasonal vs. non-seasonal.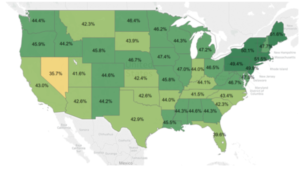 At the moment, we're thinking through what data we might be able to leverage in the upcoming segmentation (where this seasonal variable will be one candidate variable. This might include information from the BigData environment or anything that lives in the relational database. We're also weighing difficulty to get a specific variable compared to the added value we might get from gathering that data. I feel super fortunate to be able to work on projects that help us learn about our customers, so that when we message to them, we can be more relevant. Nothing is worse than receiving a communication from a company that totally misses the mark on what you're about. I find this type of work exciting, and it allows me to be creative, which is important to me. I hope you found this article enjoyable, and maybe there is a couple people out there that will actually find this applicable to their own work. I wish you lots of fun projects that leave you feeling inspired :)Again, the code I used to do this project can be found in my article here.
At the moment, we're thinking through what data we might be able to leverage in the upcoming segmentation (where this seasonal variable will be one candidate variable. This might include information from the BigData environment or anything that lives in the relational database. We're also weighing difficulty to get a specific variable compared to the added value we might get from gathering that data. I feel super fortunate to be able to work on projects that help us learn about our customers, so that when we message to them, we can be more relevant. Nothing is worse than receiving a communication from a company that totally misses the mark on what you're about. I find this type of work exciting, and it allows me to be creative, which is important to me. I hope you found this article enjoyable, and maybe there is a couple people out there that will actually find this applicable to their own work. I wish you lots of fun projects that leave you feeling inspired :)Again, the code I used to do this project can be found in my article here.

Designing and Learning With A/B Testing
I've spent the last 6 years of my life heavily involved in A/B testing, and other testing methodologies. Whether it was the performance of an email campaign to drive health outcomes, product changes, Website changes, the example list goes on. A few of these tests have been full factorial MVT tests (my fave). I wanted to share some testing best practices and examples in marketing, so that you can feel confident about how you're designing and thinking about A/B testing.As a Data Scientist, you may be expected to be the subject matter expert on how to test correctly. Or it may be that you've just built a product recommendation engine (or some other model), and you want to see how much better you're performing compared to the previously used model or business logic, so you'll test the new model vs. whatever is currently in production.There is SO MUCH more to the world of testing than is contained here, but what I'm looking to cover here is:
Determining test and control populations
Scoping the test ahead of launch
A test design that will allow us to read the results we’re hoping to measure
Test Analysis
Thoughts on automating test analysis
Choosing Test and Control PopulationsThis is where the magic starts. The only way to determine a causal relationship is by having randomized populations (and a correct test design). So it's imperative that our populations are drawn correctly if we want to learn anything from our A/B test. In general, the population you want to target will be specific to what you're testing. If this is a site test for an Ecommerce company, you hope that visitors are randomized to test and control upon visiting the website. If you're running an email campaign or some other type of test, then you'll pull all of the relevant customers/people from a database or BigData environment who meet the criteria for being involved in your A/B test. If this is a large list you'll probably want to take a random sample of customers over some time period. This is called a simple random sample. A simple random sample is a subset of your population, where every member had an equal probability of being chosen to be in the sample.
Here is a great example on how to pull a random sample from Hive: here
Also, just to be clear, writing a "select top 1000 * from table" in SQL is NOT A RANDOM SAMPLE. There are a couple different ways to get a random sample in SQL, but how to do it will depend on the "flavor" of SQL you're using.
Here is an example pulling a random sample in SQL server: here
Now that you have your sample, you'll randomly assign these people to test and control groups.There are times when we’ll need to be a little more sophisticated….Let’s say that the marketing team wants to learn about ability to drive engagement by industry (and that you have industry data). Some of the industries are probably going to contain fewer members than others. Meaning that if you just split a portion of your population into two groups, you might not have a high enough sample size in certain industries that you care about to determine statistical significance.Rather than putting in all the effort running the A/B test to the find out that you can’t learn about an industry you care about, use stratified sampling (This would involve doing a simple random sample within each group of interest).
Scoping Ahead of LaunchI've seen in practice when the marketing team doesn't see the results they want say "We're going to let this A/B test run for two more weeks to see what happens". Especially for site tests, if you run anything long enough, tiny effect sizes can become statistically significant. You should have an idea of how much traffic you're getting to the particular webpage, and how long the A/B test should run before you launch. Otherwise, what is to stop us from just running the A/B test until we get the result that we want?Sit down with marketing and other stakeholders before the launch of the A/B test to understand the business implications, what they're hoping to learn, who they're testing, and how they're testing. In my experience, everyone is set up for success when you're viewed as a thought partner in helping to construct the test design, and have agreed upon the scope of the analysis ahead of launch.
Test DesignFor each cell in an A/B test, you can only make ONE change. For instance, if we have:
Cell A: $15 price point
Cell B: $25 price point
Cell C: UI change and a $30 price point
You just lost valuable information. Adding a UI change AND a different price option makes it impossible to parse out what effect was due to the UI change or the $30 price point. We’ll only know how that cell performed in aggregate. Iterative A/B testing is when you take the winner from one test and make it the control for a subsequent A/B test. This method is going to result in a loss of information. What if the combination of the loser from test 1 and the winner from test 2 is actually the winner? We’d never know!Sometimes iterating like this makes sense (maybe you don't have enough traffic for more test cells), but we’d want to talk about all potential concessions ahead of time.Another type of test design is MVT (Multivariate). Here we'll look at a full-factorial MVT. There are more types of multivariate tests, but full-factorial is the easiest to analyze.
MVT is better for more subtle optimizations (A/B testing should be used if you think the test will have a huge impact)
Rule of thumb is at least 100,000 unique visitors per month.
You'll need to know how to use ANOVA to analyze (I will provide a follow-up article with code and explanation for how to do this analysis and link it here later)

A/B learning control monitor

a/b test treatment monitors
One illustrative example of an MVT test is below. The left (below) is the control experiences, and on the right are the 3 test treatments. This results in 2^3 = 8 treatments, because we'll look at each possible combination of test and control.
On the left: The controls would be the current experience
On the right: Cell A could be new photography (ex: friendly waving stick figure), Cell B could reference a sale and, Cell C could show new content.

chart assignment in excel for a/b testing
We can learn about all the interactions! Understanding the interactions and finding the optimal treatment when changing multiple items is the big benefit of MVT testing. The chart below shows you how each person would be assigned to one of the 8 treatments in this example.
In a future article I'll write up one of my previous MVT tests that I've analyzed, with R code.A/B Test AnalysisOne of the most important parts of test analysis is to have consistency across the business in how we analyze tests. You don't want to say something had a causal effect, when if another person had analyzed the same test, they might have reached a different conclusion. In addition to having consistent ways of determining conclusions, you'll also want to have a consistent way of communicating these results with the rest of the business. For example, "Do we share results we find with a p-value greater than .05?" Maybe we do, maybe we don't, but make sure the whole team is being consistent in their communication with marketing and other teams. Confidence intervals should always be given! You don’t want to say “Wow! This is worth $700k a year”, when really it’s worth somewhere between $100k and $1.3m. That's a big difference and could have an impact on decisions whether to roll out the change or not.Let's Automate our A/B Test Analysis!Why spend multiple hours analyzing each A/B test, when we can:
Automate removal of outliers
Build in not calculating statistical significance if the sample is not quite large enough yet
Determine statistical significance of metrics with confidence intervals and engaging graphs
See how A/B tests are performing soon after launch to make sure there aren’t any bugs messing with our results or large drops in revenue.
This also reduces opportunity for error in analysis
With a couple data entries and button pushes!This would take a while to build, and will not be a one size fits all for all of your tests. Automating even a portion could greatly reduce the amount of time spent analyzing tests!I hope this article gave you some things to be on the lookout for when testing. If you're still in school to become a Data Scientist, taking a general statistics class that covers which statistics to use and how to calculate confidence intervals is something that will benefit you throughout your career in Data Science. Otherwise, there is certainly tons of information on the internet to give you an overview of how to calculate these statistics. I personally prefer Coursera, because it's nice to sit back and watch videos on the content, knowing that the content is from well known universities.You can learn a ton through properly executed testing. Happy learning!

Learning with A/B Testing in Data Science. Data analysis, data collection , data management, data tracking, data scientist, data science, big data, data design, data analytics, behavior data collection, behavior data, data recovery, data analyst. For more on data science, visit www.datamovesme.com
Target Customers By Learning with Customer Segmentation

It’s easy to get people to buy into the idea of “Don’t test to win, test to learn.” However, when it comes to segmentation, it’s sometimes more difficult to get people over to the camp of “Don’t segment to align with your previously held ideas, segment to learn.” This may be because this saying is certainly not as short, sweet, and catchy; but I’m a strong believer in segment to learn.
I’ve been approached before with: “We did a segmentation of the market; can you tie this back to our customer base?”. This means that they did a segmentation based on survey data of the population, these people could be using your product, but they’re not necessarily using your product. This survey probably asked about the functionality they need, what they’re trying to do, and who they are.
Although sometimes we might do things with data that mystify and dazzle, we are not wizards. I cannot take your segmentation of the market and find those same segments in our customer base. Our customers are not necessarily representative of the market, and I don’t have your market survey data for all customers. But what I have is even more precious, actual behaviors that your customer has taken.
These actions include things like:
· I can see how often someone has visited our website
· Are they buying certain products and not others?
· What are they doing on our site? Reading informative articles? Visiting a lot but not converting?
· How often they’re purchasing.. Are these less expensive or more expensive products?
· If they’re calling customer service.. Did they just need help finding a product? Or were they unhappy and looking for a refund?
· How long they’ve been with us
· How were they acquired (channel)?
· Are they being upsold or cross-sold products?
This type of information is hopefully in your database, somewhere. If not, you may be able to find a way to get at it.
We could also append data from a data vendor if we have the budget. There are companies like Epsilon, Full Contact or Axiom (to name a few). If you have the budget to do this, and send them customers name, address, and some other information, they can add columns for things like:
· Income
· Race
· Education
· Employment
· Spend behavior
· Lifestyle and interests
· And more!
This would give you lots of great data to play with. The other option might be appending Census data at the zip code level. All this data could be analyzed and potentially be meaningful in creating a segmentation.
There is another instance of this problem manifesting itself more directly. When we do find ourselves in the position to do a segmentation of our customer base, I sometimes hear: “We’d like to do a segmentation, I’m thinking segments like….” Here people are explicitly using a segmentation to reinforce their previously held beliefs.
Think of how you’d be short changing yourself. Think of all the variables that you could come up with! Be innovative! Create variables that the business has never looked at before.
Try to identify a way to determine:
· Who are your seasonal customers?
· Who in your base responds to your marketing campaigns? And how?
· Time between different forms of engagement with purchasing your product or visiting the website.
You can create a segmentation around acquisition or retention, where you know what you’re trying to optimize. And these types of segmentation certainly fall into “segment to learn”, my favorite is when we use an unsupervised algorithm.
There was a great article on by john Sukup on DataScience.com, that explains some drawback of k-means and offers some different solutions. Check it out! I also used his code to make the clusters visual at the top of my article.
And once you have that output that makes sense, start learning! Learning is a manual process that typically involves doing a lot of crosstabs (at least in my experience it has been), but you can take that back to the business with a big smile and recommendations on how to target the customers in the segments. Show them what you’ve learned and let them know it’s ACTIONABLE. These are the segments that you can easily add to your database and use to build campaigns.
Summary:
Segmentation is an enjoyable experience, where you learn a ton about who your customers are. This will allow you to help determine what type of content might be most appropriate, and nurture these customers appropriately. If you're interested, I have another article on how to get buy-in from the business to get support for you big projects. That article is here. I’m amped up just thinking about data and cluster analysis. Hope you are too.

Target customers by learning with customer segmentation. Data analysis, data collection , data management, data tracking, data scientist, data science, big data, data design, data analytics, behavior data collection, behavior data, data recovery, data analyst. For more on data science, visit www.datamovesme.com.
[/et_pb_text][/et_pb_column][/et_pb_row][/et_pb_section]