
Business Science’s Time Series Course is Incredible
I’m a time series fan. Big fan. My first job out of grad school was for a utility company building econometric time series analysis and forecasting models. Lots of ARIMAs and neural nets. However, that was now over 10 years ago (don’t know how the hell that happened).
This post contains affiliate links that help to offset the cost of running the blog, plus the link gives you a special 15% discount. If you use the link, thank you!
I’m a time series fan. Big fan. My first job out of grad school was for a utility company building econometric time series analysis and forecasting models. Lots of ARIMAs and neural nets. However, that was now over 10 years ago (don’t know how the hell that happened).
In almost every position I've held in data, a question has come up that involved a time series (not a surprise that business cares about what has happened over time). Often, I was the only one who had any knowledge of time series on my team. I'm not sure why it isn't taught as a standard part of most university programs that are training data scientists, but it's just unfortunately not. I believe that understanding time series analysis is currently a great way to differentiate yourself, since many in the field are just not well versed in it.
I wanted to understand what was current in the world of applying time series analysis to business. It had been a real long time since I had given the subject some of the love and attention, and I thought taking this Business Science course would be the perfect way to do that.
My History With Business Science Courses:
I’ve previously written about Business Science’s first course, you can check it out here. I've also taken his first Shiny app course (there’s a more advanced one as well) and went from zero to Shiny app in 2 days using survey data I collected with Kate Strachnyi. It was a real win.
The app is still on my site here, just scroll down. For this little flexdashboard app I went from basically zero Shiny to having something that was useful in 2 days leveraging only the first 25% of the course. The course cannot actually be completed in 2 days. It's also worth noting that the course builds an app with much more functionality than mine. It’s a long course.
Back to the Time Series Review:
It’s broken into three different section:
Things I freakin’ love
The sexy
Everything else
Things I freakin’ love:
You’re learning about packages from the package creator. Who is going to understand a library better than the person who wrote it?. Matt built both modeltime and timetk that are used in this course. I find that super impressive. These packages are also a step up from what was currently out there from a "not needing a million packages to do what I want" perspective.
He uses his own (anonymized) data fromBusiness Science to demonstrate some of the models. I haven’t seen others do this, and I think it’s cool. It’s a real, practical dataset of his Google Analytics and Mailchimp email data with an explanation of the fields. If you don’t have analytics experience in e-commerce and are thinking about taking a role in e-commerce, definitely give some thought to this course.
I love how in-depth he gets with the subject. If you follow all that is covered in the course, you should be able to apply time series to your own data.
The Sexy:
Ok, so I’m sure some are interested in seeing just how “cutting edge” the course gets.
Once you're combining deep learning Gluon models and machine learning models using ensembling methods, you might be the coolest kid at work (but I’m not making any promises). Gluon is a package that was created by Amazon in Python. So you’ll leverage both Python and R for Gluon.
Some of the deep learning algorithms you’ll learn how to leverage are:
DeepAR
DeepVAR
N-Beats
Deep Factor Estimator
Module 18 of the course is where you'll get into deep learning. A couple years ago I might have said "deep learning, bah humbug, requires too much computing power and isn't necessary, simpler is better." As things change and progress (and computers get even more beefy) I'm definitely changing my tune. Especially as an ensemble N-Beats algorithm beat the ES-RNN's score in the M4 competition. M competitions are prestigious forecasting challenges, and they've historically been won by statistical algorithms. (I wouldn't have known this information without this course). The stuff being taught in this course is very current and the sexy new techniques that are winning the big competitions.
Here's a look at the syllabus for preparing the data and learning about the DeepAR model. You're doing log transformations, Fourier Series, and when you get to modeling the course even covers how to handle errors. I just love it. I know I'll be referring back to the course when a time series use case pops up in the future.
The course covers 17 different algorithms. I'm trying to think if I could name 17 algorithms off the top of my head… it’d take me a minute. ARIMA is obviously included, because It’s like the linear regression of time series. You’ll go through ARIMA, TBATS (a fave because you don’t need to worry about stationarity the way you do with ARIMA. I’ve used this one in industry as well).
Along with these other algos:
ARIMA Boost
Prophet Boost
Cubist
KNN
MARS
Seasonal decomposition models
Then you’ve got your ensemble algos being leveraged for time series:
GLMNET
Random Forest
Neural Net
Cubist
SVM
Strap in for 8 solid hours of modeling, hyperparameter tuning, visualizing output, cross-validation and stacking!
Everything else:
Matt (the owner of Business Science) speaks clearly and is easy to understand. Occasionally I'll put him on 1.25x speed.
His courses in general spend a good amount of time setting the stage for the course. Once you start coding, you’ll have a great understanding of where you’re going, goals, and context (and your file management will be top notch), but if you’re itching to put your fingers on the keyboard immediately, you’ll need to calm the ants in your pants. It is a thorough start.
You have to already feel comfy in R AND the tidyverse. Otherwise you’ll need to get up to speed first and Business Science has a group of courses to help you do that. You can see what's included here.
Before we finish off this article, one super unique part of the course I enjoyed was where Matt compared the top 4 time series Kaggle competitions and dissected what went into each of the winning models. I found the whole breakdown fascinating, and thought it added wonderful beginning context for the course.
In the 2014 Walmart Challenge, taking into account the “special event” of a shift in holiday sales was what landed 1st place. So you're actually seeing practical use cases for many of the topics taught in the course and this certainly helps with retention of the material.
Likewise, special events got me good in 2011. I was modeling and forecasting gas and the actual consumption of gas and number of customers was going through the roof! Eventually we realized it was that the price of oil had gotten so high that people were converting to gas, but that one tripped me up for a couple months. Thinking about current events is so important in time series analysis and we'll see it time and again. I've said it before, but Business Science courses are just so practical.
Summary:
If you do take this course, you’ll be prepared to implement time series analysis to time series that you encounter in the real world. I've always found time series analysis useful at different points in my career, even when the job description did not explicitly call for knowledge of time series.
As you saw from the prerequisites, you need to already know R for this course. Luckily, Business Science has created a bundle at a discounted price so that you can both learn R, a whole lot of machine learning, and then dive into time series. Plus you’ll get an additional 15% off the already discounted price with this link. If you're already comfortable in R and you're just looking to take the time series course, you can get 15% off of the single course here.
Edit: People have asked for a coupon to buy all 5 courses at once. That's something I'm able to do! Learn R, machine learning, beginner and advanced Shiny app development and time series here.
Key Ingredients to Being Data Driven

Companies love to exclaim "we're data driven". There are obvious benefits to being a data driven organization, and everyone nowadays has more data than they can shake a stick at. But what exactly does an organization need to be "data driven"?
Just because you have a ton of data, and you've hired people to analyze it or build models, does that make you data driven? No. That's not enough.
Although we think a lot about data and how to use it. Being data driven needs to be a priority at the executive level and become part of the culture of the organization; more so than simply having a team with the necessary capabilities.
Here are the baseline qualities that I believe are necessary to be effective in your "data driven-ness". Now I'm making up words.
To be data driven:
- Test design and analysis is owned by analytics/data science teams.
- Dashboards are already in place that give stakeholders self-serve access to key metrics. (Otherwise you'll have low value ad-hoc requests to pull these metrics, and it'll be a time sink.)
- Analytics/Data Science teams collaborate with the business to understand the problem and devise an appropriate methodology.
- Data governance and consistent usage of data definitions across departments/the organization.
- You have a data strategy.
You'll notice that there is a lack of fancy hype buzzwords above. You don't need to be "leveraging AI" or calling things AI that are in fact hypothesis tests, business logic, or simple regression.
I don’t believe fancy models are required to consider yourself data driven. A number of the points listed above are references to the attitudes of the organization and how they partner and collaborate with analytics and data science teams . I love building models as much as the next data scientist, but you can't build next level intelligence on a non-existent foundation.
To clarify, I'm not saying every decision in the organization needs to be driven by data to be data driven. In particular, if you're going to make a strategic decision regardless of the results of a test or analysis, then you should skip doing that test. I'm a big advocate of only allocating the resources to a project if you're actually going to USE the results to inform the decision.
Let's take a look at the points from above.
Test design and analysis is owned by analytics/data science teams:
Although data science and analytics teams often come up with fantastic ideas for testing. There are also many ideas that come out of a department that is not in analytics. For instance, in eCommerce the marketing team will have many ideas for new offers. The site team may want to test a change to the UI. This sometimes gets communicated to the data teams as "we'd like to test "this thing, this way". And although these non analytics teams have tremendous skill in marketing and site design, and understand the power of an A/B test; they often do not understand the different trade-offs between effect size, sample size, solid test design, etc.
I've been in the situation more than once at more than one company where I'm told "we understand your concerns, but we're going to do it our way anyways." And this is their call to make, since in these instances those departments have technically "owned" test design. However, the data resulting from these tests is often not able to be analyzed. So although we did it their way, the ending result did not answer any questions. Time was wasted.
Dashboarding is in place:
This is a true foundational step. So much time is wasted if you have analysts pulling the same numbers every month manually, or on an ad-hoc basis. This information can be automated, stakeholders can be given a tour of the dashboards, and then you won't be receiving questions like "what does attrition look like month over month by acquisition channel?" It's in the dashboard and stakeholders can look at it themselves. The time saved can be allocated to diving deep into much more interesting and though provoking questions rather than pulling simple KPIs.
Analytics/Data Science teams collaborate with the business on defining the problems:
This relationship takes work, because it is a relationship. Senior leaders need to make it clear that a data-driven approach is a priority for this to work. In addition, analytics often needs to invite themselves to meetings that they weren't originally invited to. Analytics needs to be asking the right questions and guiding analysis in the right direction to earn this seat at the table. No relationship builds over night, but this is a win-win for everyone. Nothing is more frustrating than pulling data when you're not sure what problem the business is trying to solve. It's Pandoras Box. You pull the data they asked for, it doesn't answer the question, so the business asks you to pull them more data. Stop. Sit down, discuss the problem, and let the business know that you're here to help.
Data governance and consistent usage of data definitions across departments/the organization:
This one may require a huge overhaul of how things are currently being calculated. The channel team, the product team, the site team, other teams, they may all be calculating things differently if the business hasn't communicated an accepted definition. These definitions aren't necessarily determined by analytics themselves, they're agreed upon. For an established business that has done a lot of growing but not as much governance can feel the pain of trying to wrangle everyone into using consistent definitions. But if two people try to do the same analysis and come up with different numbers you've got problems. This is again a foundation that is required for you to be able to move forward and work on cooler higher-value projects, but can't if you're spending your time reconciling numbers between teams.
You have a data strategy:
This data strategy is going to be driven by the business strategy. The strategy is going to have goals and be measurable. The analyses you plan for has a strong use case. People don't just come out of the woodwork asking for analysis that doesn't align to the larger priorities of the business. Things like "do we optimize our ad spend or try to tackle our retention problem first?" comes down to expected dollars for the business. Analytics doesn't get side-tracked answering lower value questions when they should be working on the problems that will save the business the most money.
In Summary:
I hope you found this article helpful. Being data driven will obviously help you to make better use of your data. However, becoming data driven involves putting processes into place and having agreement about who owns what at the executive level. It's worth it, but it doesn't happen over night. If you're not yet data driven, I wish you luck on your journey to get there. Your analysts and data scientists will thank you.
If you have suggestions on what else is required to be data driven, please let me know your thoughts!
A Different Use of Time Series to Identify Seasonal Customers
I had previously written about creatively leveraging your data using segmentation to learn about a customer base. The article is here. In the article I mentioned utilizing any data that might be relevant. Trying to identify customers with seasonal usage patterns was one of the variables that I mentioned that sounded interesting. And since I'm getting ready to do another cluster analysis, I decided to tackle this question.
These are my favorite types of data science problems because they require you to think a little outside the box to design a solution. Basically, I wanted to be able to tag each customer as whether or not they exhibited a seasonal pattern, this would be a first step. Later I may further build this out to determine the beginning of each customer's "off-season." This will allow us to nurture these customer relationships better, and provide a more personalized experience.
I'm a data scientist at Constant Contact, which provide email marketing solutions to small businesses. Since it is a subscription product, customers have different usage patterns that I'm able to use for this analysis.
At first, my assumption was that a good portion of these customers might be living in an area that has four seasons. You know, the ice cream shop in New England that shuts down for the winter. After thinking about it some more, if I'm looking for seasonal usage patterns, this is also going to include people with seasonal business patterns that aren't necessarily driven by the weather. People who have accounts in the education field taking summers off are going to be picked up as seasonal. Businesses in retail who have pretty consistent usage all year, but pick up their engagement at Christmas are also exhibiting a seasonal pattern. So the people who the model would determine were seasonal were not based solely on the weather, but could also be by the type of business. (Or maybe there are people that are fortunate enough to take random long vacations for no reason in the middle of the year, I want to make sure I find those people too, if they exist).
To do this analysis, I aggregated the email sending patterns of each customer with at least 2 years by customer, by month. Each customer is it's own time series. However, there were a couple complexities. One detail in particular is worth noting, customers might take a month or two (or more) off from usage. So first I had to write some code to fill in zeros for those months. I couldn't be specifying that I was looking for a yearly pattern, but only giving 8 months worth of data per year in the model, I needed those zeros. I found these missing zeros using Python, and then decided I wanted to use R for the time series/determining if a seasonal pattern was present portion. I got to use the rpy2 package in Python for the first time. Check that off the list of new packages I've wanted to try.
I fit a TBATS model for each customer in R. This is probably overkill, because TBATS was meant to deal with very complex (and potentially multiple) seasonal patterns. However, it was really simple to ask the model if it had a yearly seasonal component. Bonus, TBATS is more robust to stationarity than other methods.
Here is a picture of a customer who the model determined to be seasonal, and on the right is a customer who is obviously not seasonal, and the model agrees.
 After I had the output of my model, I went back and did a full analysis of what these customers looked like. They over-indexed in the Northeast, and were less likely to be in the West and South. Seasonal users were also more likely to self-report being in an industry like:
After I had the output of my model, I went back and did a full analysis of what these customers looked like. They over-indexed in the Northeast, and were less likely to be in the West and South. Seasonal users were also more likely to self-report being in an industry like:
- Retail
- Sports and Recreation
- Non Profits
Non seasonal users were also more likely to self-report being in an industry like:
- Auto Services
- Financial Advisor
- Medical Services
- Insurance
Customers with only 2-3 years tenure were less likely to be seasonal than more tenured customers. This could potentially be due to a couple different factors. Maybe there just wasn't enough data to detect them yet, maybe they have some period of getting acquainted with the tool (involving a different usage pattern) before they really hit their stride, or maybe they're just really not seasonal. There were more insights, but this is company data ;)Here is a map of seasonal customers over-indexing in the Northeast. Stakeholders typically enjoy seeing a nice map. Note: The split was not 50/50 seasonal vs. non-seasonal.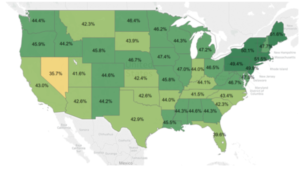 At the moment, we're thinking through what data we might be able to leverage in the upcoming segmentation (where this seasonal variable will be one candidate variable. This might include information from the BigData environment or anything that lives in the relational database. We're also weighing difficulty to get a specific variable compared to the added value we might get from gathering that data. I feel super fortunate to be able to work on projects that help us learn about our customers, so that when we message to them, we can be more relevant. Nothing is worse than receiving a communication from a company that totally misses the mark on what you're about. I find this type of work exciting, and it allows me to be creative, which is important to me. I hope you found this article enjoyable, and maybe there is a couple people out there that will actually find this applicable to their own work. I wish you lots of fun projects that leave you feeling inspired :)Again, the code I used to do this project can be found in my article here.
At the moment, we're thinking through what data we might be able to leverage in the upcoming segmentation (where this seasonal variable will be one candidate variable. This might include information from the BigData environment or anything that lives in the relational database. We're also weighing difficulty to get a specific variable compared to the added value we might get from gathering that data. I feel super fortunate to be able to work on projects that help us learn about our customers, so that when we message to them, we can be more relevant. Nothing is worse than receiving a communication from a company that totally misses the mark on what you're about. I find this type of work exciting, and it allows me to be creative, which is important to me. I hope you found this article enjoyable, and maybe there is a couple people out there that will actually find this applicable to their own work. I wish you lots of fun projects that leave you feeling inspired :)Again, the code I used to do this project can be found in my article here.

{kind=link}
{kind=link}