
Effective Data Science Presentations
If you're new to the field of Data Science, I wanted to offer some tips on how to transition from presentations you gave in academia to creating effective presentations for industry.Unfortunately, if your background is of the math, stats, or computer science variety, no one probably prepared you for creating an awesome data science presentations in industry. And the truth is, it takes practice. In academia, we share tables of t-stats and p-values and talk heavily about mathematical formulas. That is basically the opposite of what you'd want to do when presenting to a non-technical audience.If your audience is full of a bunch of STEM PhD's then have at it, but in many instances we need to adjust the way we think about presenting our technical material.I could go on and on forever about this topic, but here we'll cover:
Talking about model output without talking about the model
Painting the picture using actual customers or inputs
Putting in the Time to Tell the Story



Talking about model output without talking about the modelCertain models really lend themselves well to this. Logistic regression, decision trees, they're just screaming to be brought to life.You don't want to be copy/pasting model output into your data science presentations. You also don't want to be formatting the output into a nice table and pasting it into your presentation. You want to tell the story and log odds certainly are not going to tell the story for your stakeholders.A good first step for a logistic regression model would just be to exponentiate the log odds so that you're at least dealing in terms of odds. Since this output is multiplicative, you can say:"For each unit increase of [variable] we expect to see a lift of x% on average with everything else held constant."So instead of talking about technical aspects of the model, we're just talking about how the different drivers effect the output.
We could, however, take this one step further.
Using Actual Customers to Paint the Picture: I love using real-life use cases to demonstrate how the model is working. Above we see something similar to what I presented when talking about my seasonality model. Of course I changed his name for this post, but in the presentation I would talk about this person's business, why it's seasonal, show the obvious seasonal pattern, and let them know that the model classified this person as seasonal. I'm not talking about fourier transforms, I'm describing how real people are being categorized and how we might want to think about marketing to them. Digging in deep like this also helps me to better understand the big picture of what is going on. We all know that when we dig deeper we see some crazy behavioral patterns.Pulling specific customers/use cases works for other types of models as well. You built a retention model? Choose a couple people with a high probability of churning, and a couple with a low probability of churning and talk about those people."Mary here has been a customer for a long time, but she has been less engaged recently and hasn't done x, y, or z (model drivers), so the probability of her cancelling her subscription is high, even though customers with longer tenure are usually less likely to leave.
Putting in the Time to Tell the Story: As stated before, it takes some extra work to put these things together. Another great example is in cluster analysis. You could create a slide for each attribute, but then people would need to comb through multiple slides to figure out WHO cluster 1 really is vs. cluster 2, etc. You want to aggregate all of this information for your consumer. And I'm not above coming up with cheesy names for my segments, it just comes with the territory :).It's worth noting here that if I didn't aggregate all this information by cluster, I also wouldn't be able to speak at a high level about who was actually getting into these different clusters. That would be a large miss on my behalf, because at the end of the day, your stakeholders want to understand the big picture of these clusters.Every analysis I present I spend time thinking about what the appropriate flow should be for the story the data can tell.
I might need additional information like market penetration by geography, (or anything, the possibilities are endless). The number of small businesses by geography may not have been something I had in my model, but with a little google search I can find it. Put in the little extra work to do the calculation for market penetration, and then create a map and use this information to further support my story. Or maybe I learn that market penetration doesn't support my story and I need to do more analysis to get to the real heart of what is going on. We're detectives. And we're not just dealing with the data that is actually in the model. We're trying to explore anything that might give interesting insight and help to tell the story. Also, if you're doing the extra work and find your story is invalidated, you just saved yourself some heartache. It's way worse when you present first, and then later realize your conclusions were off. womp womp.
Closing comments: Before you start building a model, you were making sure that the output would be actionable, right? At the end of your presentation you certainly want to speak to next steps on how your model can be used and add value whether that's coming up with ideas on how you can communicate with customers in a new way that you think they'll respond to, reduce retention, increase acquisition, etc. But spell it out. Spend the time to come up with specific examples of how someone could use this output.I'd also like to mention that learning best practices for creating great visualizations will help you immensely.
There are two articles by Kate Strachnyi that cover pieces of this topic. You can find those articles here and here. If you create a slide and have trouble finding what the "so what?" is of the slide, it probably belongs in the appendix. When you're creating the first couple decks of your career it might crush you to not include a slide that you spent a lot of time on, but if it doesn't add something interesting, unfortunately that slide belongs in the appendix.I hope you found at least one tip in this article that you'll be able to apply to your next data science presentation. If I can help just one person create a kick-ass presentation, it'll be worth it.
Beginning the Data Science Pipeline - Meetings
I spoke in a Webinar recently about how to get into Data Science. One of the questions asked was "What does a typical day look like?" I think there is a big opportunity to explain what really happens before any machine learning takes place for a large project. I've previously written about thinking creatively for feature engineering, but there is even more to getting ready for a data science project, you need to get buy in on the project from other areas of the business to ensure you're delivery insights that the business wants and needs.It may be that the business has a high priority problem for you to solve, but often you'll identify projects with a high ROI and want to show others the value you could provide if you were given the opportunity to work on the project you've come up with.The road to getting to the machine learning algorithm looks something like:
Plenty of meetings
Data gathering (often from multiple sources)
Exploratory data analysis
Feature engineering
Researching the best methodology (if it's not standard)
Machine learning
We're literally going to cover the 1st bullet here in this article. There are a ton of meetings that take place before I ever write a line of SQL for a big project. If you read enough comments/blogs about Data Science, you'll see people say it's 90% data aggregation and 10% modeling (or some other similar split), but that's also not quite the whole picture. I'd love for you to fully understand what you're signing up for when you become a data scientist.
Meetings: As I mentioned, the first step is really getting buy in on your project. It's important that as an Analytics department, we're working to solve the needs of the business. We want to help the rest of the business understand the value that a project could deliver, through pitching the idea in meetings with these stakeholders. Just to be clear, I'm also not a one woman show. My boss takes the opportunity to talk about what we could potentially learn and action on with this project whenever he gets the chance (in additional meetings). After meetings at all different levels with all sorts of stakeholders, we might now have agreement that this project should move forward.
More Meetings: At this point I'm not just diving right into SQL. There may be members of my team who have ideas for data that I'm not aware of that might be relevant. Other areas of the business can also help give inputs into what variables might be relevant (they don't know they database, but they have the business context, and this project is supposed to SUPPORT their work).There is potentially a ton of data living somewhere that has yet to be analyzed, the databases of a typical organization are quite large, unless you've been at a company for years, there is most likely useful data that you are not aware of.
The first step was meeting with my team to discuss every piece of data that we could think of that might be relevant. Thinking of things like:
If something might be a proxy for customers who are more "tech savvy". Maybe this is having a business email address as opposed to a gmail address (or any non-business email address), or maybe customers who utilize more advanced features of our product are the ones we'd consider tech savvy. It all depends on context and could be answered in multiple ways. It's an art.
Census data could tell us if a customers zip code is in a rural or urban area? Urban or rural customers might have different needs and behave differently, maybe the extra work to aggregate by rural/urban isn't necessary for this particular project. Bouncing ideas off other and including your teammates and stakeholders will directly impact your effectiveness.
What is available in the BigData environment? In the Data Warehouse? Other data sources within the company. When you really look to list everything, you find that this can be a large undertaking and you'll want the feedback from others.
After we have a list of potential data to find, then the meetings start to help track all that data down. You certainly don't want to reinvent the wheel here. No one gets brownie points for writing all of the SQL themselves when it would have taken you half the time if you leveraged previously written queries from teammates. If I know of a project where someone had already created a few cool features, I email them and ask for their code, we're a team. For a previous project I worked on, there were 6 different people outside of my team that I needed to connect with who knew these tables or data sources better than members of my team. So it's time to ask those other people about those tables, and that means scheduling more meetings.
Summary: I honestly enjoy this process, it's an opportunity to learn about the data we have, work with others, and think of cool opportunities for feature engineering. The mental picture is often painted of data scientists sitting in a corner by themselves, for months, and then coming back with a model. But by getting buy in, collaborating with other teams, and your team members, you can keep stakeholders informed through the process and feel confident that you'll deliver what they're hoping. You can be a thought partner that is proactively delivering solutions.

Tips for starting a data science project. Data analysis, data collection , data management, data tracking, data scientist, data science, big data, data design, data analytics, behavior data collection, behavior data, data recovery, data analyst. For more on data science, visit www.datamovesme.com.
A Different Use of Time Series to Identify Seasonal Customers
I had previously written about creatively leveraging your data using segmentation to learn about a customer base. The article is here. In the article I mentioned utilizing any data that might be relevant. Trying to identify customers with seasonal usage patterns was one of the variables that I mentioned that sounded interesting. And since I'm getting ready to do another cluster analysis, I decided to tackle this question.
These are my favorite types of data science problems because they require you to think a little outside the box to design a solution. Basically, I wanted to be able to tag each customer as whether or not they exhibited a seasonal pattern, this would be a first step. Later I may further build this out to determine the beginning of each customer's "off-season." This will allow us to nurture these customer relationships better, and provide a more personalized experience.
I'm a data scientist at Constant Contact, which provide email marketing solutions to small businesses. Since it is a subscription product, customers have different usage patterns that I'm able to use for this analysis.
At first, my assumption was that a good portion of these customers might be living in an area that has four seasons. You know, the ice cream shop in New England that shuts down for the winter. After thinking about it some more, if I'm looking for seasonal usage patterns, this is also going to include people with seasonal business patterns that aren't necessarily driven by the weather. People who have accounts in the education field taking summers off are going to be picked up as seasonal. Businesses in retail who have pretty consistent usage all year, but pick up their engagement at Christmas are also exhibiting a seasonal pattern. So the people who the model would determine were seasonal were not based solely on the weather, but could also be by the type of business. (Or maybe there are people that are fortunate enough to take random long vacations for no reason in the middle of the year, I want to make sure I find those people too, if they exist).
To do this analysis, I aggregated the email sending patterns of each customer with at least 2 years by customer, by month. Each customer is it's own time series. However, there were a couple complexities. One detail in particular is worth noting, customers might take a month or two (or more) off from usage. So first I had to write some code to fill in zeros for those months. I couldn't be specifying that I was looking for a yearly pattern, but only giving 8 months worth of data per year in the model, I needed those zeros. I found these missing zeros using Python, and then decided I wanted to use R for the time series/determining if a seasonal pattern was present portion. I got to use the rpy2 package in Python for the first time. Check that off the list of new packages I've wanted to try.
I fit a TBATS model for each customer in R. This is probably overkill, because TBATS was meant to deal with very complex (and potentially multiple) seasonal patterns. However, it was really simple to ask the model if it had a yearly seasonal component. Bonus, TBATS is more robust to stationarity than other methods.
Here is a picture of a customer who the model determined to be seasonal, and on the right is a customer who is obviously not seasonal, and the model agrees.
 After I had the output of my model, I went back and did a full analysis of what these customers looked like. They over-indexed in the Northeast, and were less likely to be in the West and South. Seasonal users were also more likely to self-report being in an industry like:
After I had the output of my model, I went back and did a full analysis of what these customers looked like. They over-indexed in the Northeast, and were less likely to be in the West and South. Seasonal users were also more likely to self-report being in an industry like:
- Retail
- Sports and Recreation
- Non Profits
Non seasonal users were also more likely to self-report being in an industry like:
- Auto Services
- Financial Advisor
- Medical Services
- Insurance
Customers with only 2-3 years tenure were less likely to be seasonal than more tenured customers. This could potentially be due to a couple different factors. Maybe there just wasn't enough data to detect them yet, maybe they have some period of getting acquainted with the tool (involving a different usage pattern) before they really hit their stride, or maybe they're just really not seasonal. There were more insights, but this is company data ;)Here is a map of seasonal customers over-indexing in the Northeast. Stakeholders typically enjoy seeing a nice map. Note: The split was not 50/50 seasonal vs. non-seasonal.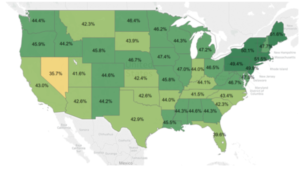 At the moment, we're thinking through what data we might be able to leverage in the upcoming segmentation (where this seasonal variable will be one candidate variable. This might include information from the BigData environment or anything that lives in the relational database. We're also weighing difficulty to get a specific variable compared to the added value we might get from gathering that data. I feel super fortunate to be able to work on projects that help us learn about our customers, so that when we message to them, we can be more relevant. Nothing is worse than receiving a communication from a company that totally misses the mark on what you're about. I find this type of work exciting, and it allows me to be creative, which is important to me. I hope you found this article enjoyable, and maybe there is a couple people out there that will actually find this applicable to their own work. I wish you lots of fun projects that leave you feeling inspired :)Again, the code I used to do this project can be found in my article here.
At the moment, we're thinking through what data we might be able to leverage in the upcoming segmentation (where this seasonal variable will be one candidate variable. This might include information from the BigData environment or anything that lives in the relational database. We're also weighing difficulty to get a specific variable compared to the added value we might get from gathering that data. I feel super fortunate to be able to work on projects that help us learn about our customers, so that when we message to them, we can be more relevant. Nothing is worse than receiving a communication from a company that totally misses the mark on what you're about. I find this type of work exciting, and it allows me to be creative, which is important to me. I hope you found this article enjoyable, and maybe there is a couple people out there that will actually find this applicable to their own work. I wish you lots of fun projects that leave you feeling inspired :)Again, the code I used to do this project can be found in my article here.

What Getting a Job in Data Science Might Look Like
I’ve read a number of articles stating how hard it was to get into Analytics and Data Science. This hasn’t been my experience, so I wanted to share. We’ll look at interviewing, the tools I currently use, what parts of industry I wasn’t prepared for in school, and what my career trajectory has looked like. But not in that particular order.It probably makes sense to quickly recap my education before we dive in!
In 2004 — Completed a BS in Mathematics from UMASS Dartmouth
Had a 3.8 GPA in my major
Took FORTRAN while there (wasn’t good at it)
No internships
I LOVE math, and loved my time in school
Honestly, not much worth noting 2004–2007. I was “finding myself,” or something.In 2007 — Started MS in Statistics at WPI Part-Time while working for Caldwell Banker Real Estate Brokerage.
The “Housing bubble” burst (the kick-off for the Great Recession), and at the same time I was lucky to be offered a Teaching Assistantship at WPI.
Moved to Worcester and finished my MS Full-Time (Finished 2010)
Used SAS & R in classes
Still no internships (economy was bad, and I had yet to learn a ton about job searching, networking, and didn’t make use of the career center)
Thought I wanted to teach at a Community College, but two Professors asked if I’d be interested in interviewing at a local utility company (and the company happened to be 3 miles from my parents house).
I interviewed at that one company and took that job.At my first post-grad school industry job, NSTAR (now Eversource) I was a Forecast Analyst using Econometric Time-Series analysis to forecast gas and electric load (read — how much gas and electricity we need to service the customers).
Everyday I was building ARIMA models, using various statistical tests to test for structural breaks in the data, unit root tests for stationarity, and I wrote a proof to explain to the Department of Public Utilities why my choice of t-stats with a value > 1 (even though the p-value might be 0.2) were beneficial to have in the model for forecasting purposes.
I built cool Neural Nets to forecast hourly electric load. This methodology made sense because there is a non-linear relationship between electric load and the weather. The model results were fantastic, and were used to make decisions on how to meet capacity on days projected to need a high load.This is the first time that I learned that once you complete a project that people care about, you’ll most likely write a deck explaining the problem and outcomes.. and then you go “on tour”. Meaning, I created PowerPoint slides and presented my work to other teams. My first PowerPoint was not very good.
It has taken years of experience to get to a point where I now think that my decks are visually appealing, appropriately tailored for the audience I’m speaking to (have the right “level” of information), and engaging.
At NSTAR I also used a tiny bit of SAS. This was in the form of re-running code previously written by someone else. It sometimes also involved slightly modifying code that someone else had written, I definitely wouldn’t consider this job SAS intensive. More like “SAS button pushing”.
The models I was building everyday were built in “Point-and-Click” software.By far, NSTAR was my most “Statistic-y” job, but Time-Series is one small part in the world of Statistics. I wanted to expand my horizons, and learned that there was A TON of opportunity in Analytics…Quick Overview of The Rest Of My Positions: Analytics Consultant, Silverlink Communications
Delivered market research, segmentations, research posters, and communication campaigns designed to support managed care organizations (MCOs), pharmacy benefit managers (PBMs), and disease management (DM) clients.
Analytics Manager, Vistaprint
Vistaprint sells business cards and other marketing products online. Their main customer base is small businesses.
Managed a team of analysts to optimize the Vistaprint website.
Held a bunch of other roles and work on a ton of different projects across Analytics
Senior Data Scientist, Constant Contact
Contant Contact offers email marketing solutions. Also Ecommerce, also targets small businesses.
I’ve been at Constant Contact now for 2 months. My first goals are:
Checking the validity of a model that is already in place.
Improving upon how they currently do testing. And then automating!
Trying to identify seasonal customers in their customer base.
Learning lots of new things!
A Note on Titles: Titles are tricky. A title may sound snazzy and not pay as much, and sometimes a lower title could pay more than you expect!As leveraging data for business purposes is becoming increasingly popular, there is even more confusion around what roles and responsibilities and skills would typically fall under a certain title. Explore all of your options!You can check out average salaries for titles on a number of different sites.
The Tools I Use (Starting From Most Basic):Everywhere I have been has used Excel. The ability to do:
Pivot tables
V-lookups
Write a simple macro using the “record” button to automate some data manipulations
These types of things can make you look like a WIZARD to some other areas of the business. (Not saying it’s right, just saying that’s how it is)
And I’ve used these things THROUGHOUT my career.
As data is getting bigger, companies are starting to move towards Tableau. I’m still new to it myself, but it has saved me from watching an Excel document take forever to save. I consider the days of waiting on large Excel files to mostly be just a thing of my past.
Data quickly becomes too large for Excel, I’ve found that anything higher than like 400k rows (with multiple columns) becomes a real chore to try and manipulate.
Pretty visualizations, can be interactive, quick, point-and-click.
Data Science Tableau chart image
Tableau can also take data in directly from SQL (a .csv, and a bunch of other formats as well).

Data Science example of a simple query
Data Science use the command line to access Hive
Data Science example of my Python code in JupyterLab
The real workhorse of a job in Data Science in SQL. It's becoming more common to pull directly to R or Python from SQL and do your data manipulation there, but this still requires connecting to the database.In school, most of the data was given to me in a nice form, all I had to bring to the table was analysis and modeling. In industry, you have millions of rows in 100’s or 1,000’s of different tables.
This data needs to be gathered from relevant tables using relevant criteria. Most of the time you’ll be manipulating the data in SQL to get it into that nice/useable form that you’re so familiar with. And this is time intensive, you’ll start to realize that a significant portion of your job is deciding what data you need, finding the data, transforming the data to be reasonable for modelling, before you ever write a line of code in R or Python.My last 3 jobs in industry have involved SQL, and I’ve only had 4 jobs.You can pull data directly from SQL into Excel or R or Python or Tableau, the list continues.
There are many different “flavors” of SQL. If you know one, you can learn any other one. In the past, I had been intimidated by job postings that would list APS or some other variant. There may be slight differences in syntax, but they’re really just asking you to know SQL. Don’t be intimidated!Below is an example of a simple query. I’m selecting some id’s, month, year, and the count of a variable “sends” based on criteria given in the “where” statement. The query also shows a couple table joins, denoted by “join”, and then I give the criteria that the join is on.Once you understand SQL, making the jump to BigData is not as daunting. Using Hive (also something that looked intimidating on a job description), is much like SQL (plus some nested data you might need to work with), you can query data from Hadoop.I use the command line to access Hive, but nice UIs are out there.
If you look closely, you’ll see my query here is just “select account_id from contacts limit 1;” all that says is “give me one account_id from the contacts table”, and it looks just like SQL.
When I was getting my Masters in Statistics, everyone was using R. Even some statisticians now are making the move to Python. Previously, all of my modeling has been in R, but I’m testing the Python waters myself!
I taught myself Python in Coursera, and I’m currently using it in my new job. That’s the beauty of the internet. Want to learn a new tool? Just go learn it, the information is at your fingertips.Below is an example of my Python code in JupyterLab. It brand-spanking new, and really my screenshot does not do it justice. You can read more about JupyterLab here: JupyterLab
A quick note. I put my Coursera classes I’ve taken under “accomplishments” in LinkedIn. It’s not a bad idea.
Things I Didn’t Know About Industry:
You might have some Opportunity for travel — Fun-ness of destination can vary
I’ve been to Vegas, Orlando, Barcelona, Windsor Ontario, NJ and MD for Work.
There is typically budget for personal development
A book you want to read that is relevant? You can probably expense it.
A course on Coursera that is relevant? You can probably expense it.
They’ll send you to conferences sometimes
Was at the Jupyter Pop-up March 21st and I’m attending the Open Data Science Conference in May.
Don’t be shy about asking your boss if there is budget available.
To most it looks like you care about and are invested in your career!
Layoffs are a thing. I recently just learned about this first hand. And my experience was great.Vistaprint decided to downsize by $20m in employee salaries (182 people).
I got a pretty sweet severance package.
Tip! You can collect unemployment and severance at the same time!
This was the first opportunity I had in years to really think about the culture, direction, and really think about my next move.Vistaprint paid for a Career Coach that helped me with:
resume (they updated both my content and formatting).
Cover letter tips (description below)
Networking
Interviewing
Negotiating!
I literally took the requirements from the job and pasted them on the left. Then took my qualifications from my resume and posted them on the right. Took less than 15 minutes for each cover letter.
Interviewing
To read my more in-depth article about the in person interview in data science, click here
To read my more in-depth article about the job hunt in data science from the first application to accepting a job offer, click
The biggest takeaways I learned from the coach and my own experience interviewing for a Data Scientist position were…
Practice answering questions in the STAR format.
https://www.vawizard.org/wiz-pdf/STAR_Method_Interviews.pdf
In one phone screen (with Kronos), I was asked all of the questions I had prepared for:
Tell me about a time you explained a technical result to a non-technical audience?
Tell me about a time you improved a process?
Tell me a time about working with a difficult stakeholder, and how it was resolved?
TWO DAYS in a row, with different companies (one of them was Spotify), I was asked to answer FizzBuzz.
Be ready for an entry level coding problem or SQL problem is the job description asks for one of those skills.
FizzBuzz: http://rprogramming.net/fizz-buzz-interview-test-in-r/
Prepare talking about one of your projects in a way that the person interviewing you (who may have little context) is able to understand. High Level, focus on outcomes. Seriously, before you start talking about the project, describe what the objective was, it’s really easy to dive into something and not realize the other person has no idea what you’re talking about.I could really keep talking forever about the topics listed above, but wanted to give a brief overview hitting a bunch of different pieces of my experience. Maybe I’ll need to elaborate more later.Thank you for reading my experience. I hope you have great success navigating your way into the field of Data Science. When you get there, I hope you find it fulfilling. I do.

What the successful data science job hunt might look like. Data analysis, data collection , data management, data tracking, data scientist, data science, big data, data design, data analytics, behavior data collection, behavior data, data recovery, data analyst. For more on data science, visit www.datamovesme.com.