
An Analysis of The Loss Functions in Keras
Welcome to my friendly, non-rigorous analysis of the computer vision tutorials in keras. Keras is popular high-level API machine learning framework in python that was created by Google. Since I'm now working for CometML that has an integration with keras, I thought it was time to check keras out. This post is actually part of a three article series. My friend Yujian Tang and I are going to tag-team exploring keras together. Glad you're able to come on this journey with us.
This particular article is about the loss functions available in keras. To quickly define a loss function (sometimes called an error function), it is a measure of the difference between the actual values and the estimated values in your model. ML models use loss functions to help choose the model that is creating the best model fit for a given set of data (actual values are the most like the estimated values). The most well-known loss function would probably be the Mean Squared Error that we use in linear regression (MSE is used for many other applications, but linear regression is where most first see this function. It is also common to see RSME, that's just the square root of the MSE).
Here we're going to cover what loss functions were used to solve different problems in the keras computer vision tutorials. There were 68 computer vision examples, and 63 used loss functions (not all of the tutorials were for models). I was interested to see what types of problems were solved and which particular algorithms were used with the different loss functions. I decided that aggregating this data would give me a rough idea about what loss functions were commonly being used to solve the different problems. Although I'm well versed in certain machine learning algorithms for building models with structured data, I'm much newer to computer vision, so exploring the computer vision tutorials is interesting to me.
Things that I'm hoping to understand when it comes to the different loss functions available in keras:
Are they all being used?
Which functions are the real work horses?
Is it similar to what I've been using for structured data?
Before we get started, if you’ve tried Coursera or other MOOCs to learn python and you’re still looking for the course that’ll take you much further, like working in VS Code, setting up your environment, and learning through realistic projects.. this is the course I used: Python Course.
Let's start with the available loss functions. In keras, your options are:

The Different Groups of Keras Loss Functions
The losses are grouped into Probabilistic, Regression and Hinge. You're also able to define a custom loss function in keras and 9 of the 63 modeling examples in the tutorial had custom losses. We'll take a quick look at the custom losses as well. The difference between the different types of losses:
Probabilistic Losses - Will be used on classification problems where the ouput is between 0 and 1.
Regression Losses - When our predictions are going to be continuous.
Hinge Losses - Another set of losses for classification problems, but commonly used in support vector machines. Distance from the classification boundary is taken into account and you're penalized if the distance is not large enough.
This exercise was also a fantastic way to see the different types of applications of computer vision. Many of the tutorials I hadn't thought about that particular application. Hopefully it's eye-opening for you as well and you don't even have to go through the exercise of looking at each tutorial!
To have an understanding of the types of problems that were being solved in the tutorials, here's a rough list:
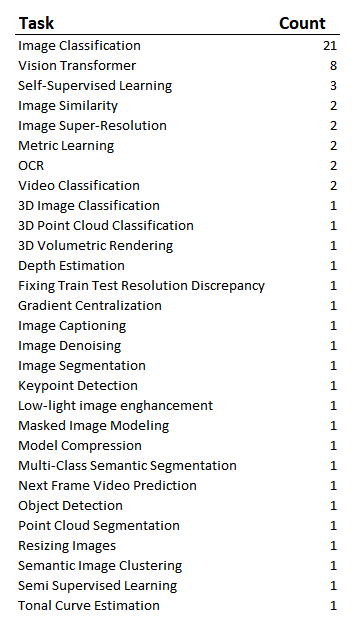
Image Classification Loss Functions
So of course, since Image classification was the most frequent type of problem in the tutorial, we're expecting to see many probabilistic losses. But which ones were they? The most obvious question is then "which loss functions are being used in those image classification problems?"

We see that the sparse categorical crossentropy loss (also called softmax loss) was the most common. Both sparse categorical crossentropy and categorical cross entropy use the same loss function. If your output variable is one-hot encoded you'd use categorical cross entropy, if your output variable is integers and they're class indices, you'd use the sparse function. Binary crossentropy is used when you only have one classifier . In the function below, "n" is the number of classes, and in the case of binary cross entropy, the number of classes will be 2 because in binary classification problems you only have 2 potential outputs (classes), the output can be 0 or 1.

Keras Custom Loss Functions
One takeaway that I also noticed is that there weren't any scenarios here where a custom defined loss was used for the image classification problems. All the classification problems used one of those 3 loss functions. For the 14% of tutorials that used a custom defined function, what type of problem were they trying to solve? (These are two separate lists, you can't read left to right).

Regression Loss Functions
Now I was also interested to see which algorithms were used most frequently in the tutorial for regression problems. There were only 6 regression problems, so the sample is quite small.

It was interesting that only two of the losses were used. We did not see mean absolute percentage error, mean squared logarithmic error, cosine similarity, huber, or log-cosh. It feels good to see losses that I'm most familiar with being used in these problems, this feels so much more approachable. The MSE is squared, so it will penalize large differences between the actual and estimated more than the MAE. So if "how much" your estimate is off by isn't a big concern, you might go with MAE, if the size of the error matters, go with MSE.

Implementing Keras Loss Functions
If you're just getting started in keras, building a model looks a little different. Defining the actual loss function itself is straight forward, but we can chat about the couple lines that precede defining the loss function in the tutorial (This code is taken straight from the tutorial). In keras, there are two ways to build models, either sequential or functional. Here we're building a sequential model. The sequential model API allows you to create a deep learning model where the sequential class is created, and then you add layers to it. In the keras.sequentional() function there are the optional arguments "layers" and "name", but instead we're adding the layers piecewise.
The first model.add line that we're adding is initializing the kernel. "kernel_initializer" is defining the statistical distribution of the starting weights for your model. In this example the weights are uniformly distributed. This is a single hidden layer model. The loss function is going to be passed during the compile stage. Here the optimizer being used is adam, if you want to read more about optimizers in keras, check out Yujian's article here.
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential()
model.add(layers.Dense(64, kernel_initializer='uniform', input_shape=(10,)))
model.add(layers.Activation('softmax'))
loss_fn = keras.losses.SparseCategoricalCrossentropy()
model.compile(loss=loss_fn, optimizer='adam')Summary
I honestly feel better after taking a look at these computer vision tutorials. Although there was plenty of custom loss functions that I wasn't familiar with, the majority of the use cases were friendly loss functions that I was already familiar with. I also feel like I'll feel a little more confident being able to choose a loss function for computer vision problems in the future. Sometimes I can feel like things are going to be super fancy or complicated, like when "big data" was first becoming a popular buzzword, but then when I take a look myself it's less scary than I thought. If you felt like this was helpful, be sure to let me know. I'm very easily findable on LinkedIn and might make more similar articles if people find this type of non-rigorous analysis interesting.
And of course, if you're building ML models and want to be able to very easily track, compare, make your runs reproducible, I highly suggest you check out the CometML library in python or R :)